
Оглавление
- 1 Что такое распределённая система
- 2 Свойства распределённой системы
- 3 Что подразумевает консенсус в распределённой системе
- 4 Реплицированный конечный автомат
- 5 Определение Проблемы Консенсуса
- 6 Недостижимость FLP
- 7 Подход 1. Допустить синхронизацию
- 8 Алгоритм Paxos
- 9 Алгоритм Raft
- 10 Минутку… А как насчёт византийской проблемы?
- 11 Проблема византийских генералов
- 12 Алгоритм DLS
- 13 Безопасность
- 14 Жизнестойкость/Устойчивость
- 15 Алгоритм PBFT
- 16 Подход 2. Недетерминизм
- 17 Введение: консенсус Накамото
- 18 Устойчивость к византийской угрозе
- 19 Вознаграждение за блоки
- 20 Устойчивость к атакам Сивиллы
- 21 P2P связи (сплетни)
- 22 Отсутствие “технической” безопасности в асинхронных средах
- 23 Консенсус Накамото и традиционный консенсус
- 24 Заключение
Оригинал статьи опубликован на сайте medium.com.

Трудно понять, как устроены распределённые системы, потому что сведения о них тоже распределены.
Просто шутка.
Что до меня, в этой шутке есть доля правды. Изучая распределённые вычисления, я долго блуждала и много раз заходила в тупик. Но теперь я, наконец, чувствую себя готовой и попытаюсь объяснить вам основы их работы.
Появление технологии блокчейн вынудило инженеров и учёных пересмотреть и подвергнуть сомнению прочно укоренившиеся парадигмы распределённых вычислений.
Я хотела бы также обсудить то глубокое влияние, которое блокчейн оказал и оказывает на современные технологии. Его появление вынудило инженеров и учёных пересмотреть и подвергнуть сомнению прочно укоренившиеся парадигмы распределённых вычислений. Возможно, никакая другая технология не способствовала так сильно ускорению прогресса в этой области, как блокчейн.
Вообще-то, распределённые системы – технология отнюдь не новая. Учёные и инженеры десятилетиями вели и ведут исследования в этом направлении. И блокчейн, вероятно, не принёс бы никакой пользы, если бы распределённых систем не существовало.
По сути, блокчейн – это новый тип распределённых систем, появившийся вместе с биткоином. И для того, чтобы узнать, как работает блокчейн, нужно понять принципы построения распределённых вычислений.
К сожалению, большая часть литературы, касающейся распределённых систем, либо трудна для понимания непрофессионалами, либо детали их устройства разбросаны по многим источникам. Существует множество архитектур, предназначенных для разных конкретных случаев, и это ещё более запутывает дело. Вместить всё это в простые рамки довольно непросто.
И поскольку вопрос так сложен, мне пришлось тщательно отбирать аспекты для объяснения. Я была вынуждена также сделать некоторые обобщения, чтобы избежать лишних сложностей, так как моей целью не было сделать из вас эксперта в данной области. Я просто хотела дать вам основные знания для того, чтобы начать увлекательное путешествие в мир распределённых систем и консенсуса.
В этой статье я объясняю следующие понятия:
- Что такое распределённая система;
- Свойства распределённых систем;
- Что означает консенсус в распределённой системе;
- Базовые алгоритмы консенсуса (например, DLS и PBFT);
- Почему консенсус Накамото имеет такое значение.
Итак, приступим.
Что такое распределённая система
Распределённая система состоит из нескольких одновременно идущих технологических процессов (например, работают несколько компьютеров), обменивающихся сообщениями друг с другом и координирующих свою работу для достижения общей цели (т.е. для решения вычислительной задачи).
Распределённая система представляет собой группу компьютеров, работающих вместе для достижения единой цели.
Проще говоря, распределённая система – это группа компьютеров, работающих вместе для получения нужного результата. И хотя процессы разделены, в представлении конечных пользователей система работает как единый компьютер.
Как я уже говорила, существуют сотни архитектур распределённых систем. Например, одиночный компьютер тоже можно рассматривать как распределённую систему: ЦПУ, модули памяти и каналы ввода-вывода являются отдельными процессами, взаимодействующими ради достижения общей цели.
В самолёте дискретные блоки совместно работают для того, чтобы доставить пассажира от пункта А в пункт Б.

Но в данном посте я сосредоточусь на распределённых системах, в которых процессами являются пространственно разнесённые компьютеры.

Я буду использовать термины “узел”, “нода”, “компьютер” или “компонент” в значении “процесс/процессор”. Для целей моего поста эти понятия равнозначны. Также я буду использовать понятие “сеть” в значении “система”.
Свойства распределённой системы
Каждая распределённая система имеет определённый набор характеристик. Среди них:
А) Параллельность
Процессы в системе работают параллельно, т.е. одновременно происходит несколько событий. Другими словами, компьютеры сети выполняют свои задачи одновременно, но независимо друг от друга.
Следовательно, необходима их координация.

В) Отсутствие глобальных часов
Для того, чтобы распределённая система работала, необходимо иметь способ определения порядка, в каком происходят события. Однако, когда несколько компьютеров работают одновременно, зачастую невозможно сказать, какое из событий произошло раньше, а какое позже, поскольку компьютеры пространственно разнесены. Другими словами, нет единых глобальных часов, которые определяют последовательность событий, происходящих на компьютерах сети.
В своей статье “Время, часы и порядок событий в распределённой системе” Лесли Лампорт (Leslie Lamport) показывает, что можно определить, какое из событий происходит раньше, а какое позже, используя следующие установки:
- Сообщения отправляются раньше, чем их получают.
- Каждый компьютер имеет свою последовательность событий.
Определив, какое события происходит непосредственно перед другим, мы можем получить частный порядок событий в системе. В статье Лампорта описывается алгоритм, для работы которого требуется, чтобы каждый компьютер “слышал” любой другой компьютер в системе. Таким образом, события могут быть упорядочены полностью на основе этого частичного упорядочения.
Однако, если упорядочение основывается на событиях, “услышанных” каждым отдельным компьютером, мы можем столкнуться с ситуацией, когда этот определённый порядок отличается от того порядка, какой воспринимает пользователь, сторонний по отношению к системе. Это означает, что алгоритм может допускать ошибки.
Лампорт также рассматривает, как такие аномалии можно предотвратить, используя правильно синхронизированные часы.
Но здесь есть серьёзное препятствие: координирование независимых часов – это очень сложная проблема компьютерной науки. Даже если вы заранее настроили множество часов, через некоторое время их данные могут стать различными. Это происходит из-за “дрейфа часов” – явления, при котором часы отсчитывают время с немного разной скоростью.
По существу, статья Лампорта показывает, что время и порядок событий являются фундаментальными проблемами в системе распределённых компьютеров, разнесённых пространственно.
С) Независимый сбой компонентов
Важнейшим аспектом в понимании работы распределённых систем является осознание того, что компоненты распределённой системы могут допускать сбои. Вот почему так важны “устойчивые к отказам распределённые вычисления”.
Невозможно создать систему, работающую без ошибок. Реальные системы всегда имеют изъяны и дефекты, процесс может давать сбой: сообщения могут теряться, искажаться или дублироваться; возможны задержки и удаление сообщений в сети; процесс может быть даже полностью нарушен, и сообщения будут отправляться в соответствии с неким злонамеренным сценарием.
Невозможно создать систему, работающую без ошибок.
Нарушения в работе системы можно разделить на три категории:
- Сбой: один из компонентов внезапно перестаёт работать (например, один из компьютеров выходит из строя);
- Бездействие: один из узлов отправляет сообщение, но оно не принимается другими узлами (например, если сообщение было удалено);
- Византийская атака (проблема Византийских генералов): один из узлов ведёт себя произвольным образом. Этот тип сбоев не касается контролируемых сред (например, дата-центров Google или Amazon), где, вероятно, “вредоносная” работа узлов невозможна. Такие ошибки возникают в т.н. “антагонистических средах”. В принципе, если децентрализованный набор независимых узлов выполняет функции нод в сети, они могут выбрать “византийскую” модель поведения. Т.е. они могут злонамеренно изменить сообщение, заблокировать его или не отправить совсем.
Учитывая всё сказанное, необходим протокол, который даст возможность системе, допускающей сбои отдельных компонентов, достигать, тем не менее, поставленной цели.
Так как любая система подвержена сбоям, основная цель, которую мы должны достигнуть при создании распределённой системы, заключается в её возможности сохранять работоспособность даже при отказе или ненормальной работе её отдельных компонентов, независимо от того, имеет ли сбой случайный или злонамеренный характер.
В целом, распределённые системы с точки зрения отказоустойчивости можно разделить на два типа:
1). Системы с простой отказоустойчивостью.
В такой системе предполагается, что все её части работают по следующему алгоритму: они или точно выполняют свою задачу, либо не работают вовсе. Система такого типа должна иметь полный контроль над узлами, дающими сбой в работе или выходящими из строя. Здесь нет нужды беспокоиться, что узлы начнут действовать произвольно или злонамеренно.
2А). Системы с византийской отказоустойчивостью.
Система с простой отказоустойчивостью не слишком полезна в неконтролируемой среде. В децентрализованных системах ноды, управляемыми независимыми участниками, обмениваются сообщениями в открытом пространстве (интернете), и мы должны предусмотреть возможность того, что они могут выбрать вредоносную или “византийскую” модель поведения.
2В). Системы с BAR-отказоустойчивостью.
Несмотря на то, что большинство систем разрабатываются с таким условием, чтобы противостоять “византийской” атаке, некоторые эксперты полагают, что такие модели имеют слишком общий характер и не учитывают возможность “рациональных” сбоев, при которых узлы начинают отклоняться от заданного поведения в том случае, если это соответствует их собственным интересам. Другими словами, узлы могут быть “честными” (лояльными) и “нечестными” (нелояльными), в зависимости от получаемых стимулов. Если стимулы достаточно весомы, то действовать “нечестно” могут начать большинство узлов.
Такие системы носят название BAR-модели, в которой учтены возможности как “византийских”, так и рациональных сбоев. Модель BAR предполагает три типа участников:
- “Византийцы”: злонамеренные ноды, стремящиеся нарушить работоспособность системы и подчинить её себе;
- “Альтруисты”: “честные” узлы, всегда следующие заданному протоколу;
- “Рационалисты”: следуют протоколу, но только в том случае, если это совпадает с их интересами.
D) Передача сообщений
Как я уже отмечала ранее, компьютеры в распределённой системе обмениваются информацией и координируются посредством “передачи сообщений” между двумя или более компьютерами. Сообщения могут передаваться при помощи любого протокола обмена, будь то HTTP, rpc или другого протокола, созданного для конкретного случая. Существует два типа сред для передачи сообщений:
Синхронный
В синхронной системе предполагается, что каждое сообщение будет доставлено в течение некоторого заданного времени.
Синхронная передача сообщений концептуально менее сложна, т.к. у пользователей есть гарантия того, что при отправке сообщения принимающий узел получит его в течение определённого периода времени. Это позволяет пользователям моделировать протокол с фиксированной верхней границей, т.е. со значением максимального времени, требуемого на доставку сообщения принимающей стороне.
Однако, такой тип среды малопригоден для использования в реальных распределённых системах, в которых компьютеры могут выходить из строя или уходить в автономный режим, а сообщения могут удаляться, дублироваться, задерживаться или поступать в произвольном порядке.
Асинхронный
В асинхронной системе передачи сообщений предполагается, что сеть может произвольно задерживать сообщения на любой период времени, дублировать их или менять их порядок. Другими словами, фиксированная верхняя граница времени, необходимого на отправку и получение сообщения, отсутствует.
Что подразумевает консенсус в распределённой системе
Мы уже знаем, что распределённые системы имеют следующие свойства:
- Параллельность процессов;
- Отсутствие глобальных часов;
- Сбои в работе;
- Передача сообщений.
Далее мы сосредоточимся на понимании того, что означает достижение “консенсуса” в распределённой системе. Но прежде надо ещё раз вспомнить то, о чём уже говорилось ранее: для распределённых вычислений могут использоваться сотни аппаратных и программных архитектур.
Самая распространённая из них носит название реплицированного конечного автомата.
Реплицированный конечный автомат
Реплицированный конечный автомат – это детерминированный конечный автомат, который реплицируется на несколько компьютеров, функционируя при этом как единый конечный автомат. Любой из таких компьютеров при этом может быть неисправен, но это не повлияет на работоспособность конечного автомата.

В случае реплицированного конечного автомата, если транзакция подтверждена, то соответствующий набор входных данных вызовет переход к следующей транзакции – атомарной операции в базе данных. Это означает, что операции или являются полностью завершенными, или они не будут завершены никогда. Набор транзакций в реплицированном конечном автомате носит название “журнала транзакций”. Логика перехода от одного правильного состояния к другому называется “логикой перехода состояния”.

Другими словами, реплицированный конечный автомат представляет собой набор распределённых компьютеров, начинающих свою работу с одного начального значения. После перехода к одному состоянию принимается решение о следующем значении. Достижение консенсуса означает, что все компьютеры должны коллективно согласовать это значение.
Таким образом, каждый компьютер задействован в сохранении согласованного журнала транзакций (т.е. компьютеры “достигают общей цели”). Реплицированный конечный автомат должен постоянно записывать данные о новой транзакции в свой “журнал”. Он должен делать это несмотря на то, что:
- Некоторые из компьютеров могут быть неисправны.
- Сеть не является полностью надёжной, и сообщения могут не доходить до адресатов, задерживаться или приходить в произвольном порядке.
- Не существует глобальных часов для определения очерёдности событий.
И это, друзья мои, и есть фундаментальная задача алгоритма консенсуса.
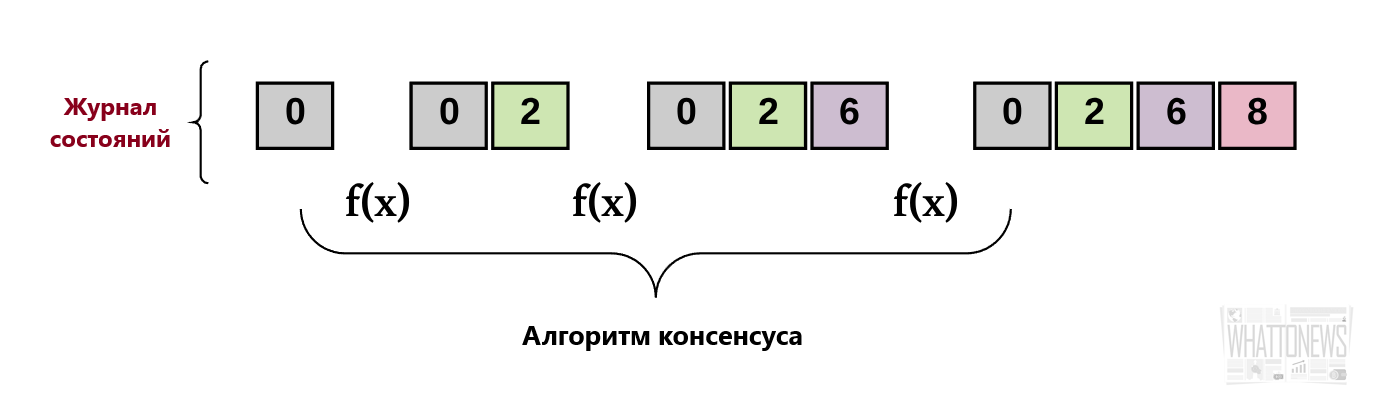
Определение Проблемы Консенсуса
Алгоритм достигает консенсуса, если он удовлетворяет следующим условиям:
- Соглашение: все исправные узлы принимают решение об одинаковом выходном значении.
- Результат: все исправные узлы обязательно принимают решение о выходном значении.
Примечание: различные алгоритмы имеют разные вариации этих условий. Например, некоторые из них разделяют понятие Соглашение на два**: Согласованность** и Всеобщность. В других есть концепции Достоверности или Целостности или Эффективности. Но такие детали выходят за рамки рассматриваемой темы.
В целом, можно разделить участников алгоритма консенсуса на три типа:
- Предлагающие, часто носят название Лидеров или Координаторов.
- Принимающие (Акцепторы) – процессы, получающие запросы от Координаторов и выдающие соответствующие значения.
- Ученики – другие процессы системы, узнающие принятые решения.
Как правило, алгоритм консенсуса можно разделить на три этапа:
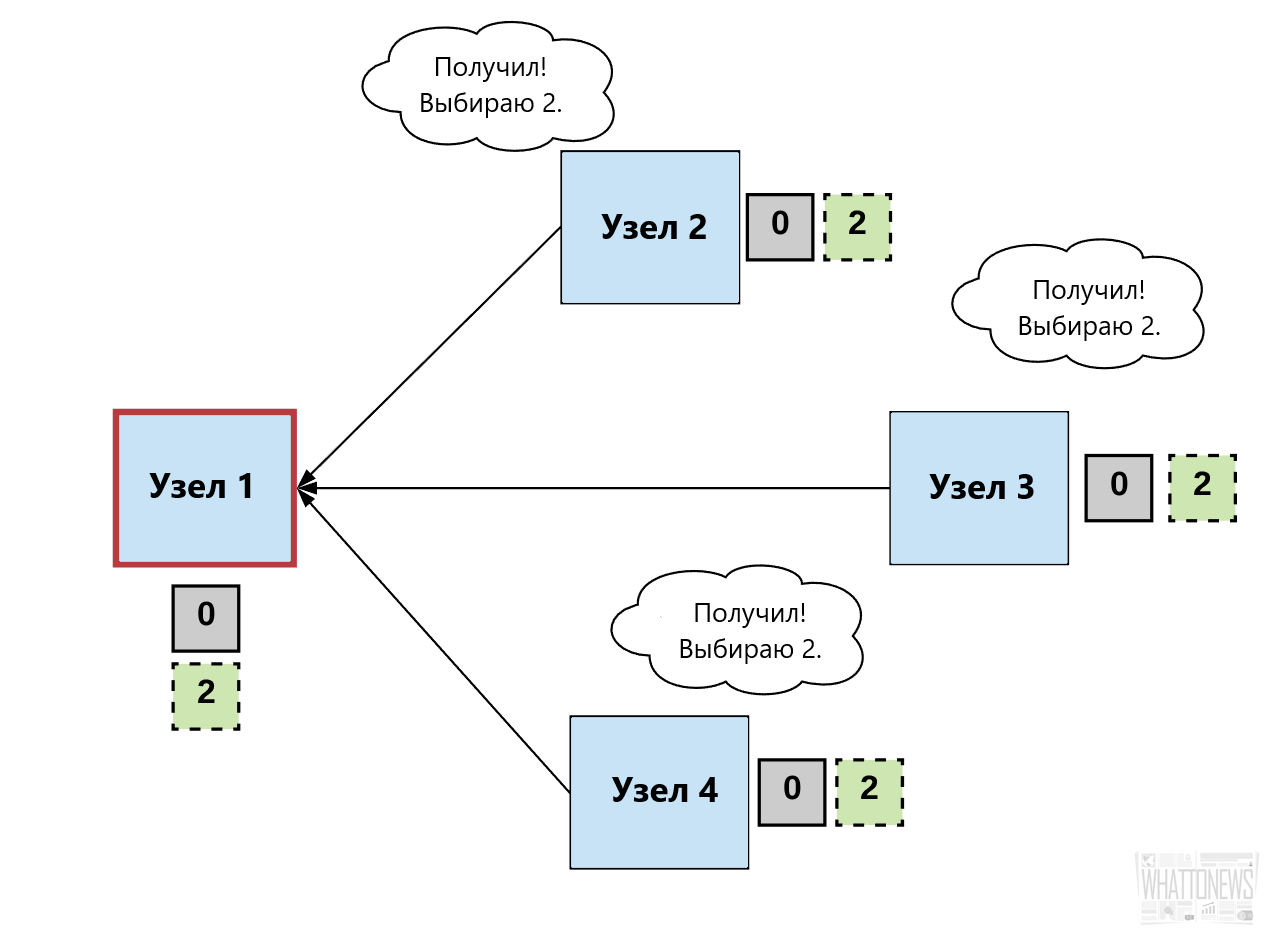
Шаг 1. Выбор.
Процессоры выбирают один процессор, который будет принимать решение (т.е. выбирают Лидера).
Лидер предлагает следующее допустимое выходное значение.
Шаг 2. Голосование.
Работающие процессоры принимают значение, предложенное лидером, проверяют его и предлагают в качестве следующего действительного значения.
Шаг 3. Решение.
Работающие процессоры должны прийти к консенсусу по одному верному выходному значению. Если значение получает пороговое количество голосов, удовлетворяющих некому критерию, то делается выбор в пользу данного значения.
В противном случае процедура начинается заново.




Важно отметить, что каждый алгоритм консенсуса отличается от других по следующим параметрам:
- Терминология (раунды, фазы и т.д.);
- Процедуры голосования;
- Критерии определения окончательного значения (к примеру, условий подтверждения).
Тем не менее, если для построения алгоритма используется общая схема с вышеперечисленными условиями, значит в нашей распределённой системе может быть достигнут консенсус.
Пока всё достаточно просто, не так ли?
Недостижимость FLP
… На самом деле это не так! (в жизни, вы, вероятно, сталкивались с такими поворотами).
Ещё раз вспомним различие между синхронными и асинхронными системами:
- В синхронных системах сообщения доставляются в течение фиксированного временного интервала.
- В асинхронных средах нет гарантии доставки сообщения.
Это различие крайне важно.
Достижение консенсуса в синхронной среде возможно, потому что мы можем делать предположения о максимальном времени, которое требуется для доставки сообщений. Таким образом, в системах такого типа мы можем позволить различным узлам системы поочерёдно предлагать новые транзакции, подсчитывать голоса для выявления транзакции, получившей наибольшее их количество, и игнорировать любую ноду, если она не выдаёт предложение в течение заданного времени.
Однако, как уже отмечалось ранее, работа в синхронной среде нецелесообразна, за исключением случаев с контролем, т.е. тех, где время ожидания предсказуемо, например дата-центров с синхронизацией с помощью атомных часов.
В реальности большинство сред не дают возможности осуществлять такую синхронизацию. Так что необходимо разрабатывать алгоритмы для сред асинхронных.
Если невозможно установить максимальное время доставки сообщений в асинхронной среде, то достижение результата становится гораздо сложнее, если вообще является возможным. Вспомним, что одним из условий достижения консенсуса является “результат”, т.е. каждый работающий узел обязан принять решение о каком-либо выходном значении.
И вот мы пришли к “доказательству FLP о невозможности (консенсуса)”.
Вероятность сбоя даже в одном процессоре делает невозможным достижения консенсуса между детерминированными асинхронными процессами.
Исследователи Фишер, Линч и Патерсон (Fisher, Lynch & Paterson, FLP) в своей работе “Невозможность распределённого консенсуса с одним нерабочим процессом” от 1985 г. показали, что даже один ошибочный процесс в детерминированной асинхронной среде делает невозможным достижение консенсуса. Было доказано, что, если процесс может дать сбой в любое непредсказуемое время, то возможно также и то, что сбой произойдёт в тот момент, когда результатом будет невозможность достижения консенсуса.

Этот результат стал камнем преткновения для пространства распределённых вычислений. Тем не менее, учёные продолжали продвигаться вперёд в попытке обойти невозможность FLP.
По сути, есть два способа обойти это ограничение:
1. Допустить синхронизацию.
2. Использовать недетерминизм (неопределённость).
Рассмотрим подробнее каждый из вариантов.
Подход 1. Допустить синхронизацию
Давайте вернёмся к результату FLP о невозможности консенсуса. По существу, он показывает, что если мы не изменим систему, то мы не добьёмся консенсуса. Другими словами, если сообщения передаются асинхронно, то результат не может быть гарантирован. Напомним, что достижение результата является обязательным условием, которое означает, что каждый рабочий узел должен в конечном счёте принять решение в пользу какого-нибудь выходного значения.
Но каким образом мы можем гарантировать, что каждый рабочий процесс примет решение, если мы не знаем, когда сообщение будет доставлено, так как сеть асинхронна?
Следует уточнить, что результат FLP не означает, что консенсус недостижим. Правильнее говорить, что из-за асинхронности консенсус не может быть достигнут в фиксированное время. Говоря, что консенсус невозможен, мы подразумеваем на самом деле, что он не всегда возможен. Это тонкое, но важное различие.
Один из способов обойти это препятствие – использовать паузы (тайм-ауты). В случае, если не принято решение о следующем значении в системе, можно взять “тайм-аут”, подождать до его окончания и начать всё сначала. И есть реальные работающие системы, которые применяют этот принцип – алгоритмы Paxos и Raft.
Алгоритм Paxos
Представленный в 1990-х годах, Paxos был первым реальным, работающим, отказоустойчивым алгоритмом консенсуса. Этот алгоритм получил широкое распространение, его правильность доказал Лесли Лампорт, и он используется для построения распределённых сервисов такими глобальными интернет-компаниями, как Google и Amazon.
Paxos работает следующим образом:
Фаза 1. Предложение/Запрос
1. Предлагающий (Заявитель) выбирает новое значение (n) и посылает его принимающим.
2. Если Принимающие (Акцепторы) получают предложение (“prepare“, n) с n большим, чем в более ранних запросах, то они посылают назад сообщение (“ack, n, n‘, v‘) или (“ack“, n, ^, ^).
3. Принимающие посылают в ответ обещание не признавать впредь предложения со значением меньше n.
4. Принимающие предлагают значение (v) максимального из предложений, которые они приняли, если таковое имеется. В противном случае они отвечают ^.
Фаза 2. Принятие запроса.
1. Если Предлагающий получает ответ от большинства Принимающих, он может поместить запрос на приём (“accept“, n, v) при данных n и v.
2. n – это число, содержащееся в предложении/запросе.
3. v – это наивысший номер среди ответов.
4. Если Принимающий получает запрос на приём (“accept“, n, v), то он акцептует предложение в том случае, если ранее он уже не ответил на предложение/запрос с номером большим, чем n.
Фаза 3. Обучение.
1. Всякий раз, когда Акцептор принимает предложение, он посылает ответ всем Ученикам (“accept”, n, v).
2. Ученики получают (“accept”, n, v) от большинства Акцепторов, принимают решение v, и отсылают (“decide“, v) всем остальным Ученикам.
3. Ученики получают (“decide“, v) и принимают решение V.
 Уф-ф-ф! И правда, можно запутаться – слишком много информации!
Уф-ф-ф! И правда, можно запутаться – слишком много информации!Однако дальше будет ещё сложнее!
Как мы уже знаем, в каждой распределённой системе обязательно есть ошибки. В алгоритме Paxos, если предложение Заявителя не проходит (например, при ошибке пропуска, omission fault), тогда решение может быть отложено – начинается Фаза 1 с новым значением, даже если предыдущие попытки закончились ничем.
Не будем углубляться в подробности, но процесс возврата к нормальной работе в таких ситуациях довольно сложен, так как необходимы непрерывность процесса и конечное принятие решения.
Основная причина, по которой Paxos сложен для понимания, заключается в том, что многие детали его реализации остаются неясными: как мы можем узнать, что предложение Заявителя не прошло? Разве мы используем синхронизированные часы, чтобы определить период ожидания (тайм-аута) для того, чтобы решить, что предложение не прошло, и нужно переходить к следующему шагу?
Для обеспечения гибкости реализации, в Paxos некоторые правила в ключевых областях остаются точно не заданными. Такие понятия, как выбор Лидеров, выявление сбоев и управление журналом, являются неопределёнными или определёнными частично.
Выбор такой архитектуры оказался одним из самых больших недостатков Paxos. Его не только невероятно сложно понять, но и сложно реализовать. В свою очередь, это создаёт большие трудности по работе в пространстве распределённых систем.
Интересно определить допущения синхронизации в Paxos. В нём, хотя тайм-ауты и не являются заданными алгоритмически, но при фактической реализации, выбор нового Заявителя после некоего периода тайм-аута необходим для достижения Решения. В противном случае, нельзя гарантировать, что Акцепторы дадут следующее выходное значение, и процесс может прекратиться.
Алгоритм Raft
В 2013 г. Диего Онгаро и Джон Оустерхаут (Ongaro, Ousterhout) опубликовали новый алгоритм консенсуса для реплицированного конечного автомата под названием Raft, основной идеей которого были простота и ясность (в отличие от Paxos).
Важной особенностью, отличающей Raft, является использование общего (коллективного) тайм-аута для получения результата (принятия решения). В Raft, если произошёл сбой и перезагрузка, необходим период ожидания как минимум в один раунд тайм-аута перед тем, как будет предпринята новая попытка объявления Лидера, и таким образом гарантировано успешное получение решения.
Минутку… А как насчёт византийской проблемы?
В то время как традиционные алгоритмы консенсуса (такие как Paxos и Raft) могут действенно работать в асинхронных средах с использованием некоторых допущений синхронности (т.е. тайм-аутов), они не являются устойчивыми по отношению к византийской проблеме, они лишь отказоустойчивы (устойчивы к сбоям).
Проблему сбоев решать легче, так как можно смоделировать процесс, имеющий лишь два состояния – работа/сбой (т.е. 0 или 1). Процесс не допускает злонамеренных или ложных действий. Таким образом, в рамках устойчивости к отказу распределённая система может быть построена на достаточности простого большинства для достижения консенсуса.
В открытых и децентрализованных системах, таких как публичный блокчейн, пользователи не имеют контроля над нодами сети. Вместо этого каждый узел принимает решение исходя из собственных целей, что может приводить к конфликтам между узлами.
В условиях с возможностью византийской проблемы, когда узлы имеют различные стимулы и могут лгать, координировать свои действия с действиями других узлов или работать независимо, для достижения консенсуса недостаточно простого большинства. Половина или более узлов, предположительно являющихся честными, могут начать действовать согласованно и начать действовать злонамеренно.
К примеру, если выбранный Лидер является византийцем и имеет сильные сетевые связи с другими узлами, он может поставить под угрозу всю систему. Как уже говорилось, необходимо моделировать систему, устойчивую или к простым отказам, или к византийской угрозе. Raft и Paxos отказоустойчивы, но не устойчивы к византийской угрозе. Они не предназначены для того, чтобы справиться со злонамеренным (вредоносным) поведением узлов.
Проблема византийских генералов
Задача построения надёжной компьютерной системы, которая может работать с процессами, предоставляющими противоречивую информацию, официально известна как Задача византийских генералов. Устойчивый к византийской угрозе протокол должен достигать своей общей цели даже при злонамеренном поведении узлов.
В своей статье “Проблема византийских генералов” Лесли Лампорт, Роберт Шостак и Маршалл Пиз (Leslie Lamport, Robert Shostak, and Marshall Pease) дали первое доказательство решения этой проблемы. Они показали, что в системе с x неверно работающими узлами («нелояльными генералами») можно достичь консенсуса только при наличии 2x+1 верно работающих процессоров («лояльных генералов»), то есть строго больше двух третей от общего числа процессоров. Другими словами, общее количество узлов должно составлять по меньшей мере 3x+1.
Рассмотрим краткое доказательство этого утверждения. Если x узлов нелояльны, то система может работать корректно при координации n-x узлов (поскольку х узлов могут быть византийцами и не отвечать). Однако, мы должны быть готовы к возможности того, что не все те х узлов, которые не дают ответа, обязательно являются нелояльными – нелояльными могут быть те х узлов, которые ответ дают! Если мы хотим, чтобы число лояльных узлов превышало количество нелояльных, нам нужно иметь их как минимум n минус х минус х > х. Таким образом, количество n >3х+1 оптимально.
Однако, алгоритмы, которые мы уже рассматривали, предназначены только для работы в синхронной среде. Вот досада! Кажется, что возможно получить лишь алгоритм или устойчивый к византийской угрозе или асинхронный. Среда, пригодная и для того, и для другого, видится гораздо более сложной.
Короче говоря, построение консенсусного алгоритма, который может как работать в асинхронной среде, так и быть устойчивым к византийской угрозе, кажется, скажем так … малореальным. И всё же, попробуем найти выход.
Такие алгоритмы как Paxos и Raft, хорошо известны и широко применяются. Однако, существует также большое количество исследований, направленных на решение проблемы консенсуса в византийско-асинхронной среде. Мы рассмотрим два алгоритма (DLS и PBFT), которые приблизили нас как никогда ранее к разрушению барьера византия/асинхронность.
Алгоритм DLS
В статье “Консенсус при наличии частичной синхронизации” Дуорк, Линч и Стокмейер (Dwork, Lynch & Stockmeyer, отсюда и название “алгоритм dns”) в значительной степени продвинулись в достижении византийско/отказоустойчивого консенсуса: в статье были даны модели того, как достичь консенсуса в частично синхронизированной системе.
Как мы помним, в синхронизированной системе существует известная фиксированная граница времени, требуемого для отправки сообщения от одного процессора к другому. В асинхронной системе фиксированных границ не существует. Частичная синхронизация находится где-то между этими двумя крайностями.
В статье DLS даются два варианта частичной синхронизации:
- Предположим, что фиксированные границы существуют для того, чтобы определить, сколько времени требуется для доставки сообщений. Но априори они неизвестны. Цель в том, чтобы достичь консенсуса независимо от установленного значения границ.
- Предположим, что верхние границы для доставки сообщений известны, но они служат только для того, чтобы зафиксировать факт отправки в некое неизвестное время (называемое также “глобальным временем стандартизации”, GST). Цель состоит в том, чтобы разработать систему, в которой может быть достигнут консенсус независимо от реального времени отправки.
Вот как работает алгоритм DLS:
1. Серия раундов делится на фазы “попытка” и “принятие решения“.
2. В каждом раунде есть свой Заявитель, и раунд начинается с того, что каждый узел сообщает значение, который считает правильным.
3. Заявитель “предлагает” то значение, которое передали как минимум n-x процессов.
4. Когда узел получает предложенное Заявителем значение, он должен зафиксировать его и затем передать эту информацию другим нодам.
5. Если Заявитель получает сообщения от х+1 узлов о том, что они остановились на некоем значении, он фиксирует это значение в качестве окончательного.
Алгоритм DLS стал крупным прорывом, поскольку он создал новую категорию возможных сетевых допущений, т.е. сделал возможным частичную синхронизацию и доказал, что при таких допущениях консенсус возможен. Другим обязательным следствием из статьи DNS является разделение вопроса достижения консенсуса в византийской и асинхронных средах на два аспекта – безопасности и жизнестойкости/устойчивости.
Безопасность
Это ещё один термин для обозначения свойства “достижения согласия”, о котором мы говорили ранее, когда каждый рабочий процесс фиксирует какое-либо значение. Если мы можем гарантировать безопасность, значит мы можем гарантировать то, что система в целом останется синхронизированной. Нам нужно, чтобы все ноды дали “согласие” на данные всего журнала транзакций целиком, несмотря на сбои и злонамеренные действия некоторых узлов. Нарушение принципа безопасности означает, что у нас появятся два или более действующих журнала транзакций.
Жизнестойкость/Устойчивость
Это другое название свойства “принятия решения”, которое мы обсуждали ранее, когда каждый исправный/лояльный узел в конце концов выбирает какое-либо выходное значение. В терминах блокчейна “жизнестойкость” означает , что блокчейн продолжает расти в объёме, присоединяя новые действительные блоки. Жизнестойкость важна, поскольку только таким путём сеть может оставаться приносящей пользу – в противном случае её работа остановится.
Как мы знаем из принципа невозможности FLP, консенсус не может быть достигнут в полностью асинхронной системе. В работе DLS показано, что допущение частичной синхронизированности для достижения жизнестойкости является достаточным условием для преодоления невозможности FLP.
Таким образом, в ней доказывается, что алгоритмы не обязательно должны использовать какие-либо допущения синхронности для обеспечения условий безопасности.
Это кажется простым, но давайте копнём чуть глубже.
Вспомним, что если ноды не выбирают какое-либо выходное значение, то система просто перестаёт работать. Итак, если сделать некоторые допущения синхронности (т.е. тайм-ауты) для того, чтобы гарантировать прерывание, а один из узлов выйдет из строя, то это также приведёт к остановке системы.
Но если мы разрабатываем алгоритм, где мы допускаем тайм-ауты (чтобы гарантировать корректность работы), мы рискуем получить два действующих журнала транзакций в том случае, если допущение синхронизации не будет выполнено.
Проектирование распределённой системы непременно требует компромиссов.
Теперь мы рискуем больше, чем ранее. Достижение жизнеспособности не имеет смысла, если отсутствует безопасность. В общем, шанс получить два разных блокчейна опаснее, чем если просто один блокчейн перестанет работать.
Распределённая система всегда связана с компромиссами. Если вы хотите преодолеть ограничение (например, невозможность FLP), то вы должны пожертвовать чем-то другим. И в данном случае разделение понятий безопасности и жизнестойкости даёт отличные результаты. Оно позволяет создать безопасную систему в асинхронной среде, однако для получения новых значений все ещё требуются тайм-ауты в той или иной форме.
Несмотря на всю ту пользу, получение которой предлагалось в работе DLS, этот алгоритм никогда не был широко реализован и не использовался в той реальности, где существует византийская угроза. Вероятно это связано с тем, что одним из допущений в алгоритме DLS было использование синхронизированных часов процессоров для того, чтобы иметь общую шкалу времени. В действительности синхронизированные часы уязвимы для различных атак и не могут дать хорошую устойчивость к византийской угрозе.
Алгоритм PBFT
Другой устойчивый к византийской угрозе алгоритм был опубликован в 1999 г. Мигелем Кастро и Барброй Лисков (Miguel Castro, Barbra Liskov), он носит название Practical Byzantine Fault-Tolerance (Практический Устойчивый к Византийской Угрозе алгоритм, PBFT). Его считали более действенным алгоритмом для систем, которые работают в византийской среде.
“Практический” в этом смысле означало, что он может работать в асинхронных средах, таких как Интернет, и имеет некоторые преимущества, которые делают его быстрее, чем предшествующие алгоритмы консенсуса. В работе Кастро и Лисков утверждалось, что более ранние алгоритмы, являясь “теоретически возможными”, были либо слишком медленными для реального использования, либо требовали синхронизации для обеспечения безопасности. Как уже отмечалось, это может быть весьма опасно при асинхронной работе.
По сути, алгоритм PBFT обеспечивал безопасность и жизнеспособность при (n-1)/3 неисправных узлов. Как уже отмечалось, это минимальное количество узлов, нужное для обеспечения устойчивости к византийской угрозе. То есть, устойчивость алгоритма казалась оптимальной.
Алгоритм обеспечивал безопасность независимо от того, сколько узлов было неисправно. Другими словами, для обеспечения безопасности синхронизации не требовалось. Однако для достижения жизнеспособности алгоритму синхронизация была нужна. В лучшем случае неисправны могли быть (n-1)/3 узлов, и задержка сообщений увеличивалась, не превышая определённого лимита времени. Следовательно, PBFT обходила невозможность FLP, используя допущения синхронизации для гарантии жизнеспособности.
Алгоритм перемещался вдоль последовательности точек, где каждая точка содержала одну “первичную” ноду (т.е. Лидера), а остальные были резервными.
Вот как работал этот алгоритм:
- Происходит новая клиентская транзакция, и она передаётся на первичный узел.
- Первичный узел переадресует её для всех резервных узлов.
- Резервные узлы выполняют транзакцию и отправляют ответ клиенту.
- Клиенту нужнох+1 ответов от резервных узлов с таким же значением. Это означает итоговый результат, и транзакция считается совершённой.
Если Лидер работал исправно, то протокол функционировал нормально. Однако, процесс обнаружения нелояльных первичных нод и выбора новых (это называлось “смена вида”) был крайне неэффективным. Например, для достижения консенсуса PBFT требовал количества сообщений, равного квадрату числа узлов, что подразумевало необходимость связи каждого компьютера со всеми другими в сети. (Примечание: всеобъемлющее объяснение работы алгоритма PBFT требует отдельного поста. Оставлю его для другого раза).
Хотя PBFT имел определённые преимущества по сравнению с предшествующими ему алгоритмами, он был не очень пригоден для реального использования (например, в публичных блокчейнах), когда количество участников велико. Но, по крайней мере, он был более приспособлен для таких вещей, как обнаружение отказов и выбор Лидеров (в отличие от Paxos).
Важно отметить и вклад PBFT. В нём содержались важные революционные идеи, которые будут исследоваться и использоваться в новых протоколах консенсуса (особенно в мире пост-блокчейн).
Возьмём, к примеру, Tendermint – новый консенсусный алгоритм, который испытал сильное влияние PBFT. На этапе подтверждения Tendermint использует двух-шаговое голосование (как и PBFT) для выбора окончательного значения. Ключевое отличие алгоритма Tendermint заключается в том, что он разработан для практических нужд.
Например, в Tendermint новый Лидер ротируется в каждом новом раунде. Если Лидер текущего раунда не отвечает в установленный период времени, он утрачивает право Лидерства, и алгоритм просто переходит к следующему раунду с новым Лидером. На самом деле, это имеет более глубокий смысл, чем связь point-to-point каждый раз, когда требуется view-change и выбирается новый лидер.
Подход 2. Недетерминизм
Как уже отмечалось, большинство устойчивых к византийской угрозе протоколов консенсуса в конечном счёте используют некоторые допущения синхронизации для того, чтобы обойти невозможность FLP. Однако, существует ещё один способ для этого – недетерминизм.
Введение: консенсус Накамото
Итак, определим, что f(x) определяется таким образом, что Заявитель и множество Акцепторов должны координировать свои действия и связываться друг с другом, чтобы принять решение о новом значении.
Традиционные алгоритмы консенсуса не очень хорошо масштабируются.
Достичь хорошей масштабируемости в традиционных алгоритмах консенсуса довольно сложно, так как это требует наличия данных о состоянии каждого узла в сети и о его взаимодействии с каждым другим узлом (квадрат от количества узлов). Короче говоря, в такой ситуации невозможны хорошая масштабируемость и работа в открытых системах, не требующих разрешения, когда каждый может присоединиться к сети или покинуть её в любое время.
Консенсус Накамото с блеском делает всё это возможным. Вместо необходимости согласия каждого узла с новым значением, функция f(x) работает таким образом, что ноды соглашаются с вероятностью правильности значения. Что же всё это значит?
Устойчивость к византийской угрозе
Вместо выборов Лидера и последующей координации узлов каждый-с-каждым, консенсус определяется на основе того, какой узел сможет решить вычислительную задачу быстрее всего. Каждый новый блок в блокчейне биткоина добавляется тем узлом, который быстрее решает эту головоломку. Сеть продолжает строить эту цепочку, и каноническая цепочка – это та, которая требует наибольшего совокупного усилия (т.е. имеет наибольшую совокупную сложность).
Наибольшая длина цепочки блоков не только служит доказательством её истинности, но и доказательством того, что она принадлежит пулу узлов с наибольшей мощностью ЦПУ. Таким образом, до тех пор, пока большая часть мощности ЦПУ контролируется честными (лояльными) нодами, они будут продолжать генерировать самую длинную цепочку блоков и отражать атаки злоумышленников.
Вознаграждение за блоки
Консенсус Накамото работает с тем предположением, что узлы будут затрачивать вычислительные усилия, чтобы получить принятия решения о выборе следующего блока. Уникальность алгоритма в том, что он экономически стимулирует узлы к решению сложных вычислительных задач для получения возможности получить вознаграждение за блоки.
Устойчивость к атакам Сивиллы
Доказательство работы proof-of-Work, необходимое для решения вычислительной задачи, делает протокол Накамото устойчивым по своей природе к атакам Сивиллы. При этом нет необходимости в PKI (Public Key Infrastructure, Инфраструктура Открытых Ключей) или других схемах аутентификации.
P2P связи (сплетни)
Важным вкладом консенсуса Накамото является использование протокола сплетен (Gossip Protocol). Это подходит больше для одноранговых (p2p) сред, где не предполагается передача данных между рабочими узлами. Вместо этого, предполагается, что узел связан с неким подмножеством других нод. Далее используется p2p протокол, где сведения передаются между узлами как “сплетни”.
Отсутствие “технической” безопасности в асинхронных средах
В консенсусе Накамото гарантия безопасности является вероятностной – строится самая длинная цепочка блоков, и добавление каждого нового блока снижает вероятность того, что вредоносный узел сможет построить другую действующую цепочку.
То есть, консенсус Накамото не гарантирует безопасность в асинхронной среде на техническом уровне. Давайте посмотрим, почему это так.
Для того, чтобы система была безопасной в асинхронной среде, нужно иметь возможность поддерживать согласованный неизменяемый журнал транзакций несмотря на асинхронность сети. По-другому это можно описать так: любая нода в любой момент времени может уйти офлайн, а позднее вернуться в режим онлайн и использовать исходное состояние блокчейна для определения последнего по времени правильного состояния, вне зависимости от состояния сети. Любой “честный” узел имеет возможность запросить информацию о состоянии блокчейна в любой момент прошлого, а вредоносный узел лишён возможности обмануть честные узлы, дав им мошенническую информацию под видом правдивой.
Консенсус Накамото технически не гарантирует безопасность в асинхронной среде.
В алгоритмах, рассмотренных ранее, такая возможность есть, так как на каждом этапе мы имеем определённое значение. Если мы знаем значение на конкретном шаге, мы можем определить предшествующее значение. Причина, по которой биткоин не безопасен “технически” при работе в асинхронной среде, заключается в том, что допускается разделение цепочки блоков, что теоретически даёт возможность злоумышленнику, обладающему достаточно большой хеш-мощностью, в момент разделения создать альтернативное ответвление от цепочки быстрее, чем честная сеть создаст своё, и в этой альтернативной цепочке он может попытаться изменить запись о своих транзакциях для того, чтобы незаконно вернуть свои потраченные деньги.
Впрочем, такой сценарий потребовал бы огромного количества хеш-мощности и денежных затрат.
В сущности, неизменяемость блокчейна биткоина определена тем, что большинство майнеров фактически не хотят создания альтернативной цепочки блоков. Почему? Потому что слишком сложно сгруппировать и скоординировать достаточное количество хеш-мощности, чтобы сеть могла принять альтернативную цепочку. Иными словами, вероятность создания альтернативной цепочки настолько мала, что её можно считать нулевой.
Консенсус Накамото и традиционный консенсус
Для практического использования консенсус Накамото является устойчивым к византийским атакам. Но при его использовании консенсус явно не достигается таким же способом, как при использовании традиционных протоколов. Поэтому изначально он считался не подходящим для использования в среде с византийской опасностью.
По своей структуре консенсус Накамото позволяет принять участие в открытом блокчейне любому количеству нод, и никому не нужно знать весь состав участников. Важность этого прорыва невозможно переоценить. Спасибо тебе, Накамото!
Более простой, чем предыдущие алгоритмы консенсуса, консенсус Накамото устраняет сложность соединений от узла к узлу (point-to-point), выбор Лидера, коммуникационные издержки в квадратичном масштабе от количества узлов и т.п. Вам требуется только лишь запустить программное обеспечение биткоина на любом компьютере, и вы сможете начать майнинг.
Это невероятно упрощает практическое применение алгоритма консенсуса Накамото. Это действительно более практичный “родственник” алгоритма PBFT.
Заключение
Итак, мы вкратце рассмотрели основы распределённых систем и консенсуса. Путь их развития был непростым, долгим и извилистым, и потребовал глубоких исследований и применения изобретательности для того, чтобы уйти так далеко. Надеюсь, что мой пост поможет вам хоть немного понять устройство сферы распределённых вычислений.
Консенсус Накамото – это поистине та инновация, которая позволила новому поколению исследователей, учёных, разработчиков и инженеров продолжить работу по поиску новых путей в разработке протоколов консенсуса.
И мы уже имеем совершенно новое семейство протоколов, отличающихся от консенсуса Накамото – Proof-of-Stake. Однако это я оставлю для следующего поста.
Примечание: Чтобы не превращать пост в книгу, я оставила за рамками многие важные алгоритмы и документы. Например, проект Common Coin Бена Орра также использовал вероятностный подход, но не был достаточно устойчивым. Другие алгоритмы, такие как Hash Cash тоже использовали PoW, но только для борьбы со спамом в электронной почте и атак типа “отказ в обслуживании” (denial-of-service). Есть множество протоколов консенсуса, о которых я не сказала ни слова! Но, надеюсь, я помогла вам получить представление о консенсусе Накамото и его отличиях от традиционных алгоритмов.